> ## Documentation Index
> Fetch the complete documentation index at: https://api-docs.ollang.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Review, Editing, and Human Review Workflows
> Understand AI-only workflows, AI + Human Review workflows, assignment behavior, editing operations, and delivery logic inside the Ollang Project Management Dashboard.
## Overview
The Ollang Project Management Dashboard supports both:
* AI-only workflows,
* and AI + Human Review workflows.
This allows organizations to:
* fully automate localization,
* integrate internal reviewers,
* assign external linguists,
* onboard dubbing studios,
* or combine AI and human review pipelines.
The workflow selected during Order creation determines:
* how the Order is processed,
* who can review it,
* and how final delivery occurs.
***
# Workflow Types
Fully AI-generated localization workflow that remains editable and assignable after generation.
Workflow where human linguists or editors review, refine, and deliver the generated output.
***
# AI-only Workflow
## Overview
AI-only workflows generate localization outputs using AI orchestration pipelines without automatically assigning a human reviewer.
However:
* AI-only Orders remain editable,
* rerunnable,
* and assignable after generation.
This means organizations can still:
* internally review outputs,
* assign linguists later,
* or reprocess workflows if needed.
***
# AI-only Workflow Behavior
```text theme={null}
Source Asset
↓
AI Processing
↓
Generated Output
↓
Editable / Assignable / Downloadable
```
***
# Important Clarification
AI-only does not mean the Order is locked or non-editable.
Project Management Users can still:
* edit outputs,
* rerun workflows,
* assign editors,
* assign linguists,
* or deliver outputs manually.
***
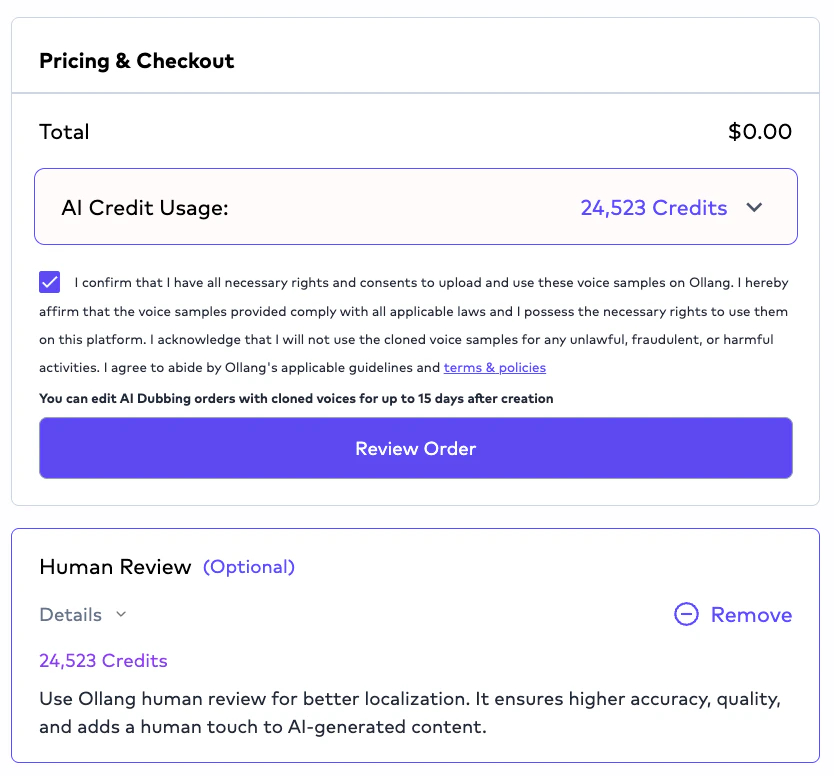
# AI + Human Review Workflow
## Overview
AI + Human Review workflows combine:
* AI-generated localization,
* with human editing and review operations.
This workflow is commonly used for:
* enterprise localization,
* accessibility workflows,
* high-visibility media,
* regulated industries,
* and premium localization pipelines.
 ***
# AI + Human Review Pipeline
```text theme={null}
Source Asset
↓
AI Processing
↓
Human Assignment
↓
Editing / Review
↓
Final Delivery
```
***
# Human Review Assignment Logic
Human review assignments will involve Ollang-managed reviewers.
Organizations can request human review support from Ollang.
***
# Example Assignment Workflow
```text theme={null}
Project Manager creates Order
↓
AI generates output
↓
Ollang's Project assigns the order to a Linguist
↓
Linguist edits and delivers Order
```
***
# Editor Interface
Editors and linguists perform operational review inside the:
* Editor Interface.
The Editor Interface supports:
* subtitle editing,
* transcription editing,
* timing adjustments,
* dubbing review,
* speaker management,
* and multilingual delivery operations.
***
# Subtitle Editing Capabilities
Editors can:
* edit subtitle text,
* modify timing,
* split subtitle segments,
* merge subtitle segments,
* optimize CPS/CPL,
* adjust readability,
* and refine localization quality.
***
# Dubbing Editing Workflows
For AI Dubbing workflows, editors can:
* review generated translations,
* refine dialogue,
* optimize pacing,
* modify localized text,
* and rerun synthesis workflows.
Depending on the workflow:
* resynthesis (Text-To-Speech Operations) may occur after edits.
***
# Segment-Level Editing Behavior
If a subtitle or dubbing segment is split:
* edits operate at segment level.
Example:
```text theme={null}
Original segment:
"Welcome to the platform."
Segment split into:
- "Welcome"
- "to the platform."
If one segment changes later:
- only the edited segment may require regeneration.
```
***
# Human Delivery Workflow
After editing is completed:
* editors or linguists deliver the Order.
Delivery updates:
* Order status,
* Project visibility,
* and downstream operational workflows.
The finalized outputs then appear inside:
* the Project Management Dashboard.
***
# AI + Human Review Pipeline
```text theme={null}
Source Asset
↓
AI Processing
↓
Human Assignment
↓
Editing / Review
↓
Final Delivery
```
***
# Human Review Assignment Logic
Human review assignments will involve Ollang-managed reviewers.
Organizations can request human review support from Ollang.
***
# Example Assignment Workflow
```text theme={null}
Project Manager creates Order
↓
AI generates output
↓
Ollang's Project assigns the order to a Linguist
↓
Linguist edits and delivers Order
```
***
# Editor Interface
Editors and linguists perform operational review inside the:
* Editor Interface.
The Editor Interface supports:
* subtitle editing,
* transcription editing,
* timing adjustments,
* dubbing review,
* speaker management,
* and multilingual delivery operations.
***
# Subtitle Editing Capabilities
Editors can:
* edit subtitle text,
* modify timing,
* split subtitle segments,
* merge subtitle segments,
* optimize CPS/CPL,
* adjust readability,
* and refine localization quality.
***
# Dubbing Editing Workflows
For AI Dubbing workflows, editors can:
* review generated translations,
* refine dialogue,
* optimize pacing,
* modify localized text,
* and rerun synthesis workflows.
Depending on the workflow:
* resynthesis (Text-To-Speech Operations) may occur after edits.
***
# Segment-Level Editing Behavior
If a subtitle or dubbing segment is split:
* edits operate at segment level.
Example:
```text theme={null}
Original segment:
"Welcome to the platform."
Segment split into:
- "Welcome"
- "to the platform."
If one segment changes later:
- only the edited segment may require regeneration.
```
***
# Human Delivery Workflow
After editing is completed:
* editors or linguists deliver the Order.
Delivery updates:
* Order status,
* Project visibility,
* and downstream operational workflows.
The finalized outputs then appear inside:
* the Project Management Dashboard.
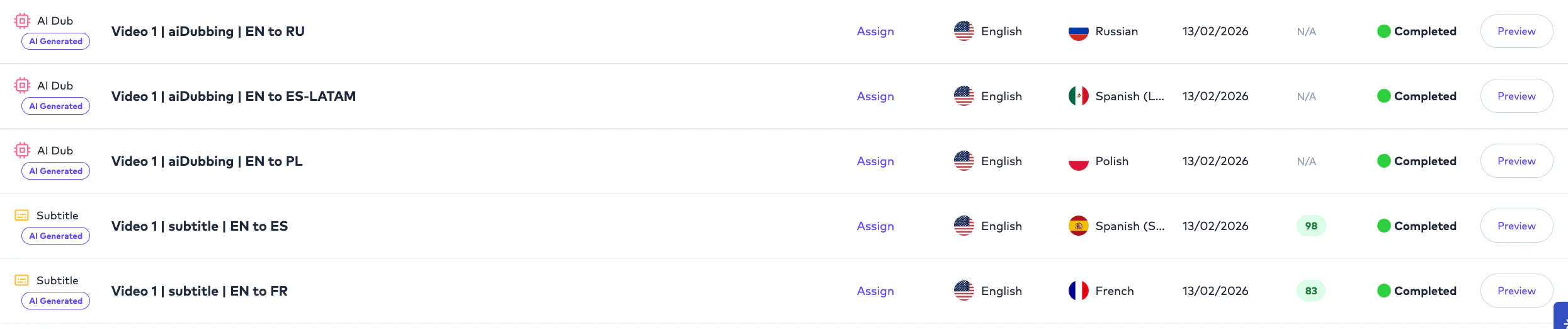 ***
# Review Visibility Rules
Project Management Users generally have visibility into:
* all organizational Projects,
* all Folders,
* and operational workflows.
Editors and linguists only see:
* explicitly assigned Orders.
***
# Example Visibility Structure
```text theme={null}
Folder contains:
- 10 Projects
- 200 Orders
Editor assigned:
- 5 Orders
Result:
- Editor only sees assigned Orders.
```
***
# AI QC and Human Review
Human review workflows may operate alongside:
* AI QC evaluation,
* QC thresholds,
* and workflow automation rules.
Organizations may configure workflows such as:
```text theme={null}
If QC score < threshold
↓
Automatically assign linguist
```
This enables:
* scalable review operations,
* automated escalation,
* and multilingual QA workflows.
***
# Review Visibility Rules
Project Management Users generally have visibility into:
* all organizational Projects,
* all Folders,
* and operational workflows.
Editors and linguists only see:
* explicitly assigned Orders.
***
# Example Visibility Structure
```text theme={null}
Folder contains:
- 10 Projects
- 200 Orders
Editor assigned:
- 5 Orders
Result:
- Editor only sees assigned Orders.
```
***
# AI QC and Human Review
Human review workflows may operate alongside:
* AI QC evaluation,
* QC thresholds,
* and workflow automation rules.
Organizations may configure workflows such as:
```text theme={null}
If QC score < threshold
↓
Automatically assign linguist
```
This enables:
* scalable review operations,
* automated escalation,
* and multilingual QA workflows.
 ***
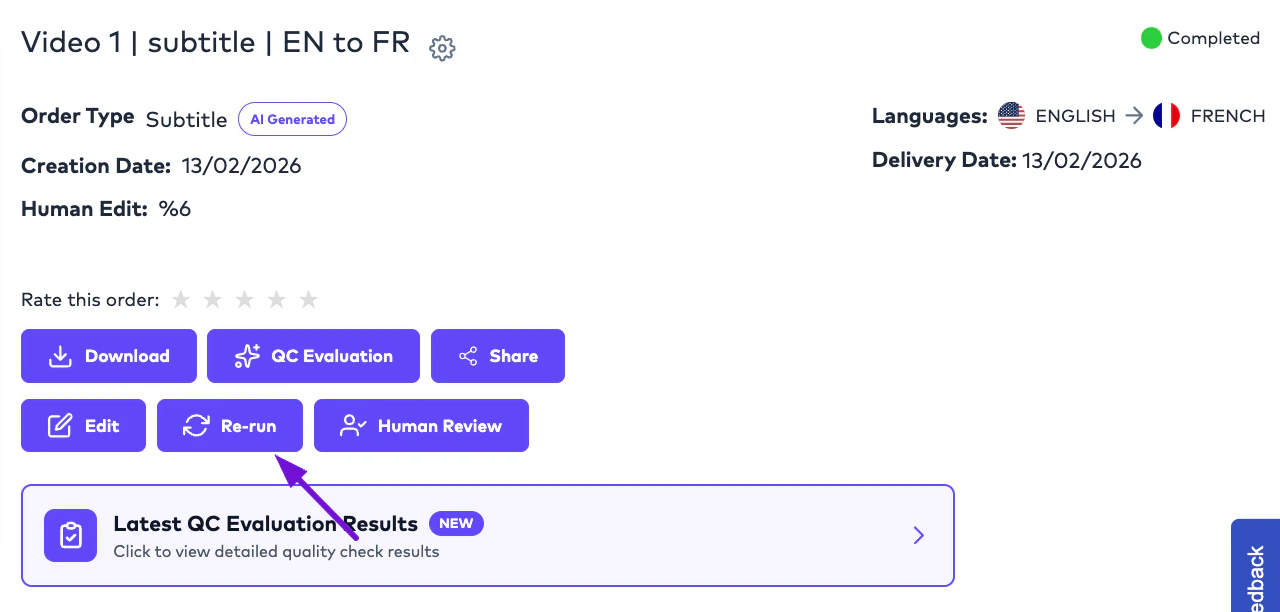
# Rerun Workflows
Orders may be rerun after:
* subtitle edits,
* workflow changes,
* translation refinements,
* or synthesis adjustments.
Rerunning may regenerate:
* subtitles,
* translations,
* dubbing outputs,
* or downstream deliverables.
***
# Rerun Workflows
Orders may be rerun after:
* subtitle edits,
* workflow changes,
* translation refinements,
* or synthesis adjustments.
Rerunning may regenerate:
* subtitles,
* translations,
* dubbing outputs,
* or downstream deliverables.
 ***
# Studio Dubbing Review Workflows
Studio Dubbing workflows support:
* externally managed recording operations,
* uploaded dubbing assets,
* and final delivery coordination.
Studios may:
* upload final mixes,
* upload dubbing vocals,
* or coordinate delivery assets inside the platform.
***
# AI QC Evaluation
## Overview
AI QC Evaluation allows Project Management Users to automatically evaluate subtitle localization quality using configurable AI-based quality assessment.
This workflow is currently available for:
* Subtitle Translation Orders.
The feature helps organizations:
* evaluate localization quality,
* identify linguistic weaknesses,
* benchmark translation performance,
* and improve multilingual consistency before delivery.
***
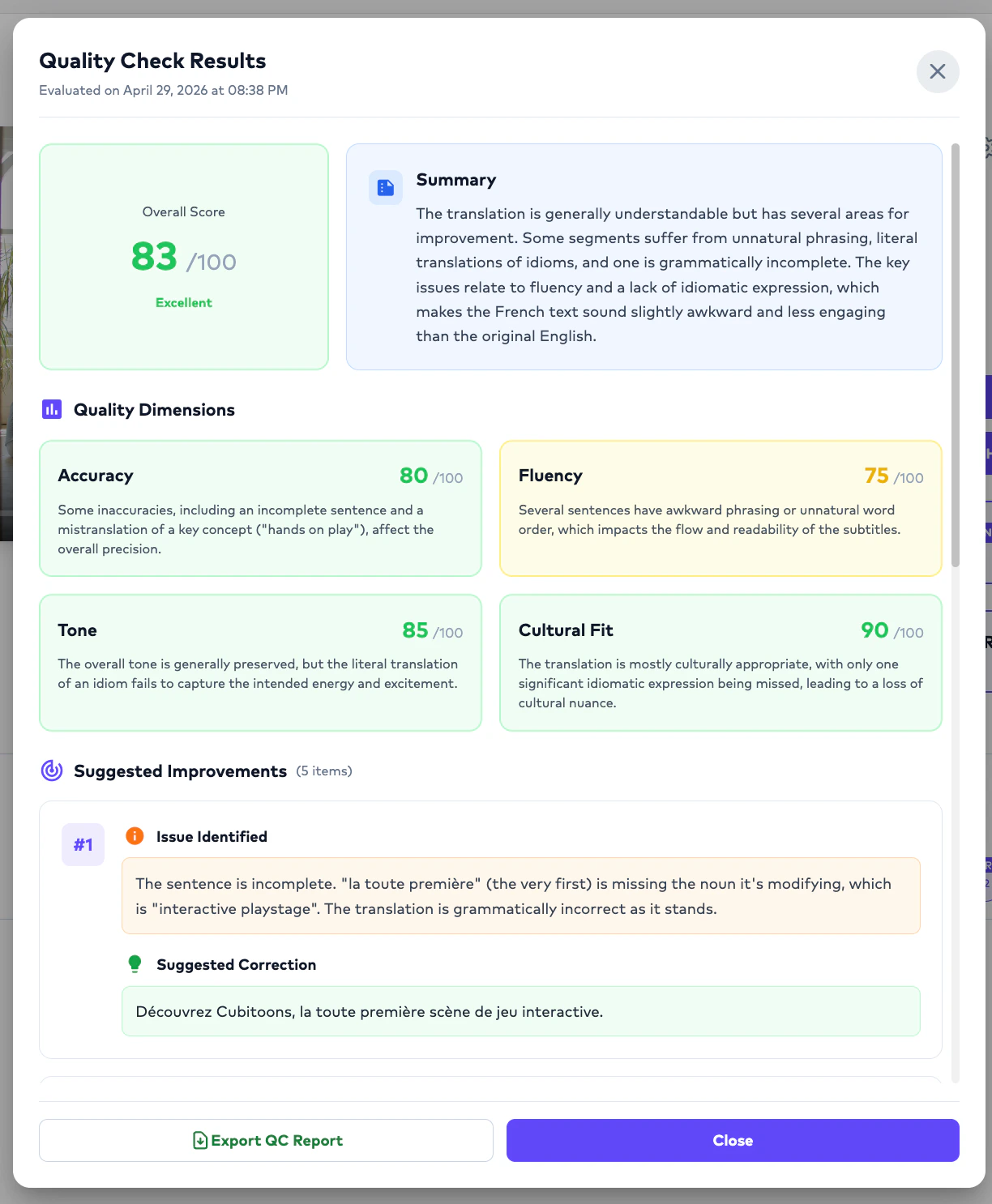
# How AI QC Evaluation Works
Project Management Users can run an AI-powered quality evaluation directly from the Order interface.
***
# Studio Dubbing Review Workflows
Studio Dubbing workflows support:
* externally managed recording operations,
* uploaded dubbing assets,
* and final delivery coordination.
Studios may:
* upload final mixes,
* upload dubbing vocals,
* or coordinate delivery assets inside the platform.
***
# AI QC Evaluation
## Overview
AI QC Evaluation allows Project Management Users to automatically evaluate subtitle localization quality using configurable AI-based quality assessment.
This workflow is currently available for:
* Subtitle Translation Orders.
The feature helps organizations:
* evaluate localization quality,
* identify linguistic weaknesses,
* benchmark translation performance,
* and improve multilingual consistency before delivery.
***
# How AI QC Evaluation Works
Project Management Users can run an AI-powered quality evaluation directly from the Order interface.
 Workflow:
```text theme={null}
Subtitle Order
↓
Click "QC Evaluation"
↓
Configure Evaluation Settings
↓
Select Model + Prompt
↓
Run Evaluation
↓
QC Results Generated
```
The system evaluates subtitle quality based on:
* predefined evaluation criteria,
* optional custom criteria,
* selected evaluation model,
* and prompting instructions.
# Default Evaluation Criteria
The platform currently includes four built-in evaluation dimensions:
Evaluates whether the translation preserves the intended meaning of the source content.
Evaluates readability, grammar, and natural language quality.
Evaluates whether tone, voice, and intent remain consistent with the original content.
Evaluates whether localized content feels contextually and culturally appropriate for the target audience.
# Custom Evaluation Criteria
Organizations may optionally define:
* custom evaluation criteria.
This allows teams to evaluate content based on:
* brand guidelines,
* legal requirements,
* subtitle standards,
* accessibility expectations,
* or domain-specific localization rules.
Example:
```text theme={null}
Custom Criteria:
"Medical Terminology Compliance"
Prompt:
Evaluate whether approved medical terminology was consistently preserved.
```
# AI QC Results
Once evaluation is completed:
The system generates:
* QC scoring,
* evaluation reasoning,
* criteria-level analysis,
* and quality observations.
These results help organizations:
* validate localization quality,
* identify problem areas,
* and decide whether human review is required.
Workflow:
```text theme={null}
Subtitle Order
↓
Click "QC Evaluation"
↓
Configure Evaluation Settings
↓
Select Model + Prompt
↓
Run Evaluation
↓
QC Results Generated
```
The system evaluates subtitle quality based on:
* predefined evaluation criteria,
* optional custom criteria,
* selected evaluation model,
* and prompting instructions.
# Default Evaluation Criteria
The platform currently includes four built-in evaluation dimensions:
Evaluates whether the translation preserves the intended meaning of the source content.
Evaluates readability, grammar, and natural language quality.
Evaluates whether tone, voice, and intent remain consistent with the original content.
Evaluates whether localized content feels contextually and culturally appropriate for the target audience.
# Custom Evaluation Criteria
Organizations may optionally define:
* custom evaluation criteria.
This allows teams to evaluate content based on:
* brand guidelines,
* legal requirements,
* subtitle standards,
* accessibility expectations,
* or domain-specific localization rules.
Example:
```text theme={null}
Custom Criteria:
"Medical Terminology Compliance"
Prompt:
Evaluate whether approved medical terminology was consistently preserved.
```
# AI QC Results
Once evaluation is completed:
The system generates:
* QC scoring,
* evaluation reasoning,
* criteria-level analysis,
* and quality observations.
These results help organizations:
* validate localization quality,
* identify problem areas,
* and decide whether human review is required.
 ***
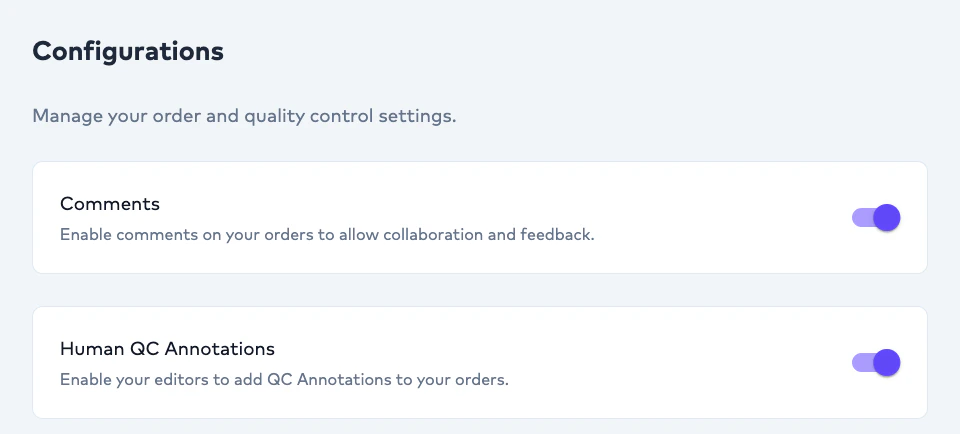
# Human QC Annotation
## Overview
Human QC Annotation enables linguists and editors to evaluate AI-generated subtitle output using structured quality tags.
Unlike AI QC Evaluation:
* Human QC Annotation is performed manually by a linguist during review.
This workflow allows organizations to:
* audit AI quality,
* identify recurring issues,
* benchmark linguistic weaknesses,
* and improve future localization workflows.
# When Human QC Annotation Happens
Human QC Annotation occurs:
```text theme={null}
AI generates subtitle Order
↓
Order assigned to linguist/editor
↓
Linguist reviews segments
↓
Annotations added where needed
↓
Order delivered
↓
Annotation Summary generated
```
This workflow is available only when:
* Human QC Annotation is enabled in configuration settings.
***
# Human QC Annotation
## Overview
Human QC Annotation enables linguists and editors to evaluate AI-generated subtitle output using structured quality tags.
Unlike AI QC Evaluation:
* Human QC Annotation is performed manually by a linguist during review.
This workflow allows organizations to:
* audit AI quality,
* identify recurring issues,
* benchmark linguistic weaknesses,
* and improve future localization workflows.
# When Human QC Annotation Happens
Human QC Annotation occurs:
```text theme={null}
AI generates subtitle Order
↓
Order assigned to linguist/editor
↓
Linguist reviews segments
↓
Annotations added where needed
↓
Order delivered
↓
Annotation Summary generated
```
This workflow is available only when:
* Human QC Annotation is enabled in configuration settings.
 ***
# Important Operational Behavior
Linguists do not need to annotate every subtitle segment.
Annotations are only added:
* to segments where issues are identified.
This keeps the workflow:
* efficient,
* scalable,
* and operationally practical.
***
# Important Operational Behavior
Linguists do not need to annotate every subtitle segment.
Annotations are only added:
* to segments where issues are identified.
This keeps the workflow:
* efficient,
* scalable,
* and operationally practical.

 # Human QC Categories
Editors can tag subtitle segments using predefined categories:
Used when translated meaning is incorrect or incomplete.
Used when approved terminology or glossary usage is inconsistent.
Used when AI introduces fabricated, missing, or unsupported content.
Used when factual correctness or contextual truthfulness is affected.
# Severity Levels
Each annotation can additionally include:
* severity classification.
Available severity levels include:
Small issue with limited localization impact.
Significant issue affecting localization quality or readability.
Severe issue requiring immediate correction.
***
# Example Annotation Workflow
Example subtitle segment:
```text theme={null}
Source:
"We launched the feature globally."
AI Translation:
"We launched the bug globally."
```
Human QC Annotation:
```text theme={null}
Category: Accuracy
Severity: Major
Issue:
Incorrect translation altered intended meaning.
```
***
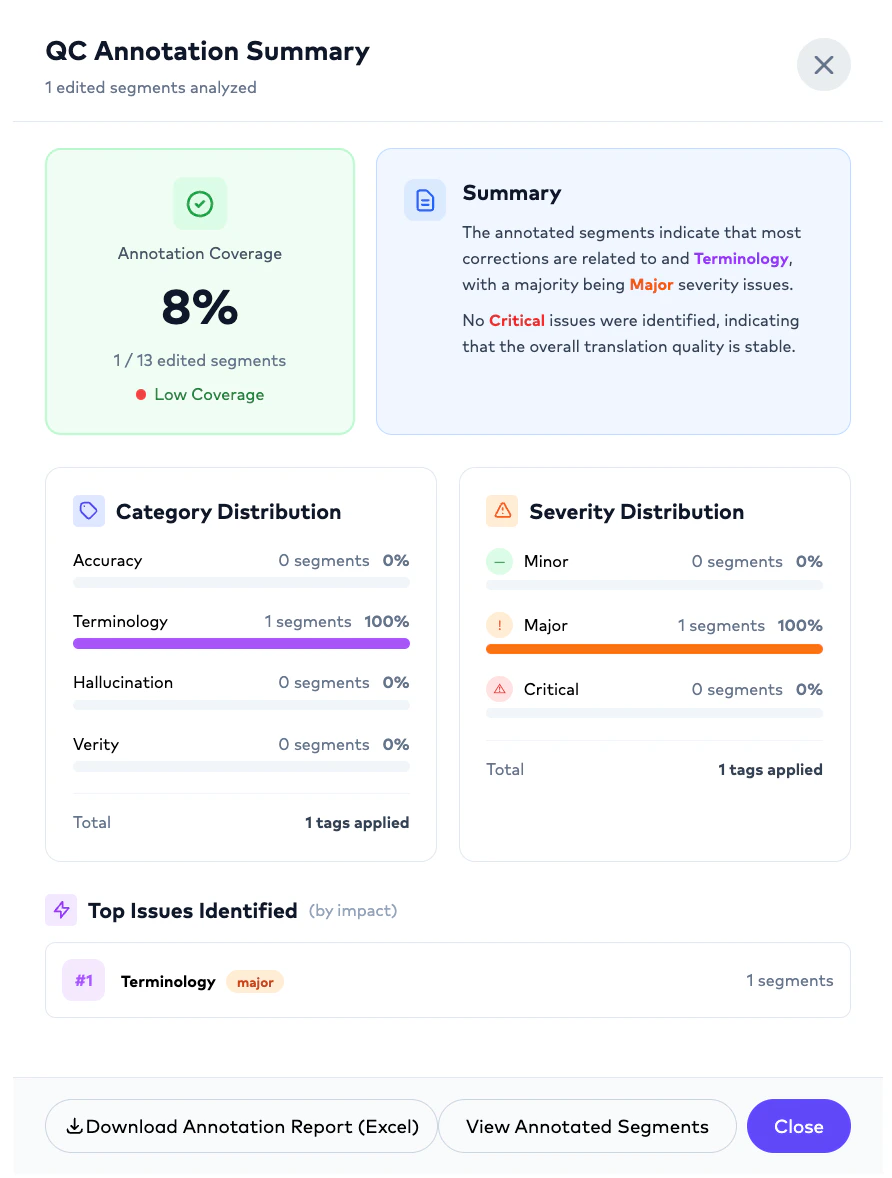
# Annotation Summary
Once the linguist delivers the Order:
Project Management Users can access:
* Human QC Annotation results.
The platform generates an annotation summary including:
* number of annotated segments,
* category distribution,
* severity distribution,
* top recurring issues,
* and localization quality insights.
# Human QC Categories
Editors can tag subtitle segments using predefined categories:
Used when translated meaning is incorrect or incomplete.
Used when approved terminology or glossary usage is inconsistent.
Used when AI introduces fabricated, missing, or unsupported content.
Used when factual correctness or contextual truthfulness is affected.
# Severity Levels
Each annotation can additionally include:
* severity classification.
Available severity levels include:
Small issue with limited localization impact.
Significant issue affecting localization quality or readability.
Severe issue requiring immediate correction.
***
# Example Annotation Workflow
Example subtitle segment:
```text theme={null}
Source:
"We launched the feature globally."
AI Translation:
"We launched the bug globally."
```
Human QC Annotation:
```text theme={null}
Category: Accuracy
Severity: Major
Issue:
Incorrect translation altered intended meaning.
```
***
# Annotation Summary
Once the linguist delivers the Order:
Project Management Users can access:
* Human QC Annotation results.
The platform generates an annotation summary including:
* number of annotated segments,
* category distribution,
* severity distribution,
* top recurring issues,
* and localization quality insights.
 # Example Annotation Summary
```text theme={null}
Human QC Annotation Summary
Segments Reviewed: 245
Annotated Segments: 18
Category Distribution:
- Accuracy: 8
- Terminology: 5
- Hallucination: 3
- Verity: 2
Severity Distribution:
- Minor: 10
- Major: 6
- Critical: 2
```
# Exporting Annotation Reports
Human QC Annotation reports can be downloaded as:
* Excel (.xlsx)
This enables:
* enterprise auditing,
* vendor benchmarking,
* linguist performance reviews,
* and multilingual quality reporting.
***
# AI QC vs Human QC Annotation
Automated evaluation using configurable prompts, models, and quality criteria.
Manual linguist-driven quality tagging performed during subtitle review.
Organizations commonly combine both workflows to benchmark AI quality while also collecting human linguistic feedback.
# Important Operational Notes
Yes. AI-only Orders remain editable, rerunnable, and assignable to the inner team members after generation.
Yes. Orders may be assigned internally or externally depending on operational workflows.
Yes. Organizations may onboard their own editors, linguists, agencies, or dubbing studios.
Yes. Human review support can also be coordinated through Ollang-managed linguists.
No. Editors only see explicitly assigned Orders.
Yes. Orders may be rerun after workflow modifications, translation changes, or dubbing refinements.
# Example Annotation Summary
```text theme={null}
Human QC Annotation Summary
Segments Reviewed: 245
Annotated Segments: 18
Category Distribution:
- Accuracy: 8
- Terminology: 5
- Hallucination: 3
- Verity: 2
Severity Distribution:
- Minor: 10
- Major: 6
- Critical: 2
```
# Exporting Annotation Reports
Human QC Annotation reports can be downloaded as:
* Excel (.xlsx)
This enables:
* enterprise auditing,
* vendor benchmarking,
* linguist performance reviews,
* and multilingual quality reporting.
***
# AI QC vs Human QC Annotation
Automated evaluation using configurable prompts, models, and quality criteria.
Manual linguist-driven quality tagging performed during subtitle review.
Organizations commonly combine both workflows to benchmark AI quality while also collecting human linguistic feedback.
# Important Operational Notes
Yes. AI-only Orders remain editable, rerunnable, and assignable to the inner team members after generation.
Yes. Orders may be assigned internally or externally depending on operational workflows.
Yes. Organizations may onboard their own editors, linguists, agencies, or dubbing studios.
Yes. Human review support can also be coordinated through Ollang-managed linguists.
No. Editors only see explicitly assigned Orders.
Yes. Orders may be rerun after workflow modifications, translation changes, or dubbing refinements.